

Mistral released its first speech understanding models on Tuesday. Dubbed Voxtral, it is an open-source audio generation artificial intelligence (AI) model that not only turns text into speech but can also understand text to generate speech as a response natively. These models are available in two sizes of 24 billion parameters and three billion parameters. The Paris-based AI firm highlighted that not only is Voxtral available to download for free, but the company is also making it available at an affordable rate via application programming interface (API).
Mistral Brings an Open Solution for Native Speech Generation
In a newsroom post, Mistral calls voice “humanity’s first interface,” highlighting it as a foundational pillar of communication. As AI models become more capable, the French AI company said it was important to bring human-computer interactions to this natural interface.
However, there are some gaps in this effort. Mistral claimed today’s voice-focused AI models can be grouped in two categories: open-source models that have a high word error rate and limited semantic understanding; and closed proprietary models that are very expensive and not accessible to all.
Voxtral, an open-source model with native semantic understanding, is aimed at closing this gap, the company added. There are three models in total — Voxtral Small with 24B parameters, Voxtral Mini with 3B parameters, and Voxtral Mini Transcribe with 3B parameters. All of these models are available to the open community with the Apache 2.0 license that allows both academic and commercial usage.
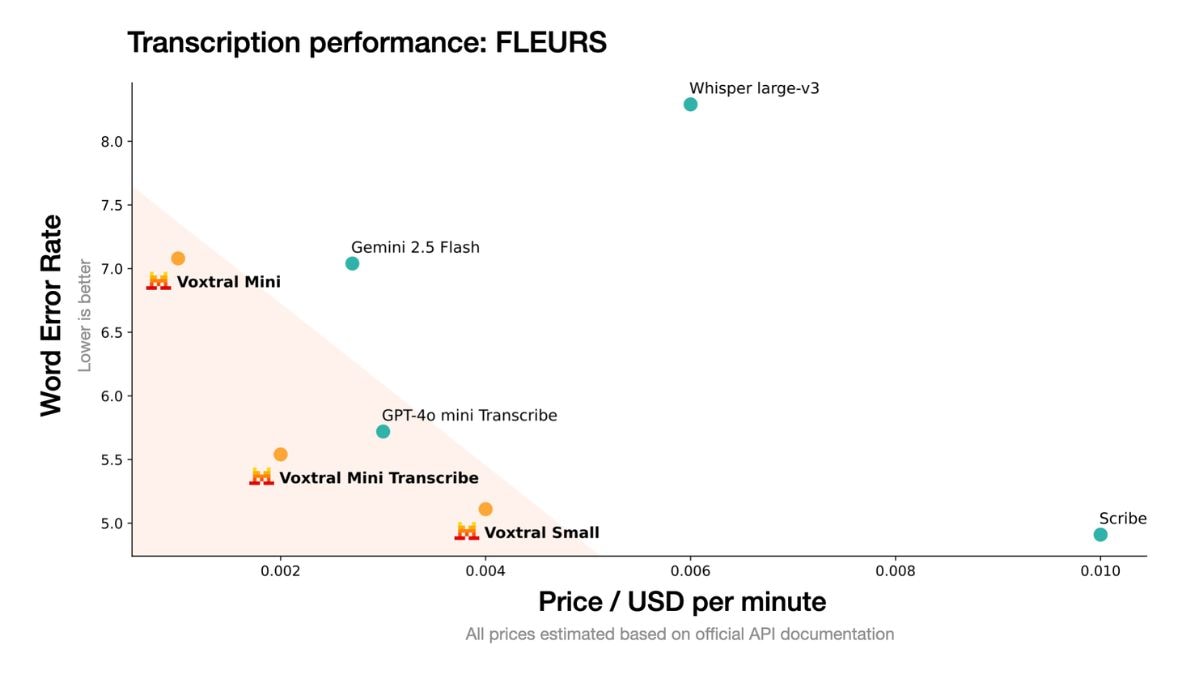
Mistral claims Voxtral offers the best balance between performance and cost efficiency
Photo Credit: Mistral
Notably, Voxtral Small is the company’s premium model aimed at production-scale applications, while the Voxtral Mini is designed for local and edge deployments. The Voxtral Mini Transcribe is focused on transcription-related tasks and is said to outperform OpenAI Whisper.
Voxtral models have a context window of 32,000 tokens, which translates to up to 30 minutes of transcription or 40 minutes of voice understanding. It can also answer questions about audio content and generate summaries natively. Additionally, Voxtral is also capable of detecting multiple languages, including English, Spanish, French, Portuguese, Hindi, German, Dutch, Italian, and more.
These models are built on top of Mistral Small 3.1, Voxtral models also offer function calling via voice, so users can command the AI system without having to type anything. Mistral claims that the Vostral Small model outperforms GPT-4o mini Transcribe and Gemini 2.5 Flash across tasks, and surpasses ElevenLabs Scribe in multilingual capabilities.
The Voxtral models can be downloaded from the company’s Hugging Face listing, accessed via API at a starting price of $0.001 (roughly Re. 1) per minute, or can be tried out via Mistral’s Le Chat platform.




